-
[Pandas] 집계함수 살펴보기내일배움캠프/Python 2024. 7. 22. 21:27
오늘은 pandas의 집계함수인 pivot, pivot_table 그리고 groupby에 대해서
알아보려고 합니다.
얼핏보면 비슷하지만 많이 달라서 자세하게 알고 있어야
나중에 필요할 때 제대로 사용할 수 있 수 있습니다.

데이터 프레임 일단 오늘 사용할 데이터 프레임 하나를 만들었습니다.
날짜와 지역, 그리고 카테고리별로 판매량과 이익이 나와있습니다.
Pivot
pivot 테이블은 복잡한 데이터 프레임에서
필요한 몇 개의 행과 열을 가져와
새로운 데이터 프레임을 가져오는 역할을 합니다.
pivot은
데이터프레임 명.pivot(index = '인덱스 명', columns = '컬럼 명', values = '값 명')
문법을 가지고 있습니다.
날짜를 인덱스로 지역을 컬럼으로 총판매를 값으로 넣어서
새로운 데이터프레임을 만들어 보았습니다.
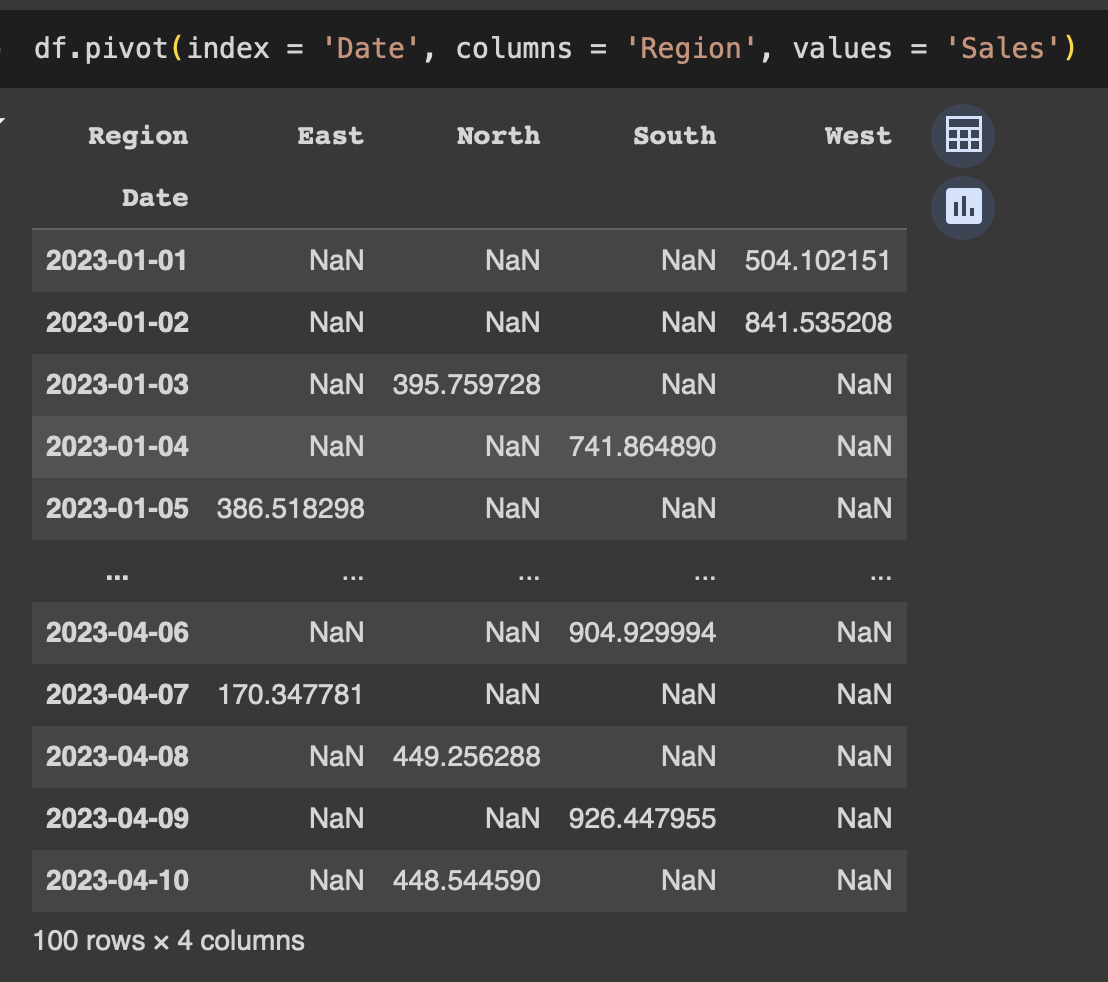
피벗 pivot은 간단해서 사용하기 좋지만
몇 가지 단점이 있습니다.
바로 집계함수를 사용하지 못한다는 것과
중복을 처리할 수 없어
pivot 결과에 중복되는 값이 있을 경우
오류가 발생한다는 것입니다.

오류 발생 중복값이 있는 열로 인덱스를 지정해줬더니
바로 에러가 발생했습니다.
인덱스는 고유값을 가져야하는데
pivot이 중복처리를 해주지 못하기 때문에
오류가 발생하는 것입니다.
Pivot_table
pivot_table도 마찬가지로 데이터프레임을 피벗해주는데
pivot과 다른 점은 중복 처리도 하고
집계 함수를 사용해줄 수도 있습니다.
pivot_table은
데이터프레임 명.pivot_table(index = '인덱스 명', columns = '컬럼 명', values = '값 명', aggfunc = '집계 함수')
문법을 가지고 있습니다.
날짜를 인덱스로 지역을 컬럼으로 판매량의 합을 값으로하여
pivot_table을 만들어 보았습니다.

피벗 테이블 해당 날짜와 장소의 판매량의 총합을 잘 보여줍니다.
Groupby
데이터를 특정 기준으로 그룹화하고,
그룹별로 집계함수를 사용하여 요약된 값을 보여줍니다.
마치 SQL구문의 group by와 똑같은 역할을 합니다.
중복을 없애주고, 집계함수와 함께 사용하여 요약된 값을 받습니다.
group by가 내놓는 것은 기본적으로 다차원 배열이 아닙니다.

앞에서 보던 데이터프레임과 다른 형태를 가지고 있습니다.
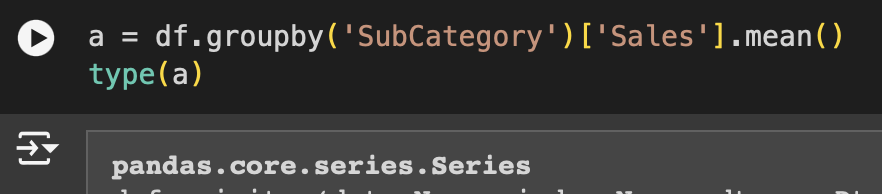
시리즈 확인해보니 series를 내놓았습니다.
하지만 집계에 사용하는 데이터를 여러 개 두면
데이터프레임으로 내놓기도 합니다.

데이터프레임 Pivot_table과 Groupby 차이
groupby는 그룹화를 하여
그룹과 관련한 데이터를 집계 함수를 통해 요약합니다.
따라서 복잡한 데이터 집계 작업을 할 때 유용합니다.
pivot_table은 관심있는 데이터를
행과 열로 설정합니다.
데이터를 보기 편하고
교차 분석을 하기 좋습니다.
데이터 분석을 하는 목적을 생각해보고
거기에 맞게 적용하면 되겠습니다!
'내일배움캠프 > Python' 카테고리의 다른 글
[Python] 자료구조 - 스택 (0) 2024.08.02 [Python] 파이썬 소수 구하기 알고리즘 (0) 2024.07.24 [Python] for문에서 리스트를 사용할 때 주의해야하는 것 (0) 2024.07.19 [Python] 파이썬 문제 해결 전략 (5) (2) 2024.07.18 [Python] 정규표현식 (기초편) (0) 2024.07.15